Wie man bösartigen Traffic mit HTTP2/TLS Fingerprinting erkennt
In der täglichen Risikokontrolle und Anti‑Scraping‑Praxis stoßen Teams häufig auf ein Problem: traditionelles IP‑Blocking und UA‑Identifizierung reichen nicht mehr aus.
Deshalb haben in den letzten zwei Jahren immer mehr Sicherheitsteams begonnen, einem technischen Ansatz Aufmerksamkeit zu schenken—HTTP2/TLS fingerprint Identifizierung.
Als Nächstes besprechen wir, wie TLS fingerprint genutzt wird, um anomalen Traffic und automatisierte Crawler zu identifizieren, und wie dieser Ansatz in realen Geschäftsszenarien umgesetzt wird.

1. Die Rolle der HTTP2/TLS fingerprint Erkennung im Anti-Scraping
Viele Automatisierungstools können sich auf der HTTP‑Ebene gut tarnen, werden jedoch durch HTTP2/TLS fingerprint Erkennung leicht enttarnt.
Der Grund ist einfach: Einen Browser zu simulieren ist leicht, aber den zugrunde liegenden Netzwerk‑Stack zu simulieren ist schwierig. Echte Browser haben in HTTP/2 typischerweise:
• Spezifische Frame-Sequenzen
• Feste Prioritätseinstellungen
• Spezifische Header-Reihenfolge
Automatisierungstools hingegen verwenden häufig Standardbibliotheken, abnorme Frame-Sequenzen oder Header-Reihenfolgen, die nicht zu echten Browsern passen—all dies erzeugt abnorme HTTP2 fingerprint.
In realen Geschäftsszenarien kombinieren viele Teams TLS Fingerprinting mit HTTP2 fingerprint Erkennung, fügen dann Browser fingerprint Prüfungen und Verhaltensanalyse hinzu, um ein mehrschichtiges Identifikationssystem zu bilden.
2. Wie man TLS fingerprint zur Identifizierung automatisierter Crawler nutzt
Schritt 1: TLS fingerprint normaler Nutzer sammeln
Sammeln Sie zunächst Zugriffsdaten von echten Nutzern—z. B. JA3 fingerprint der neuesten Chrome-Versionen, TLS-Eigenschaften von Safari und Unterschiede über Betriebssysteme hinweg—um eine Basis-fingerprint Datenbank aufzubauen.
Schritt 2: Abnorme TLS fingerprint identifizieren
Wenn eine neue Anfrage eintrifft: Extrahieren Sie das TLS fingerprint, gleichen Sie es mit der fingerprint Datenbank ab und bestimmen Sie, ob es sich um einen abnormen Client handelt.
Häufige Anomalien sind:
• Nicht-Browser TLS fingerprint
• Bekannte fingerprint von Crawler-Frameworks
• Anfragen mit häufig wechselndem fingerprint
Diese können direkt in eine Risiko-Warteschlange eingeordnet werden.
Schritt 3: Kombination mit Browser fingerprint Erkennung
TLS Fingerprinting allein ist wirkungsvoll, es wird jedoch empfohlen, es mit Browser fingerprint Erkennung zu kombinieren. Zum Beispiel:
• Echte Nutzer vs. automatisierte Crawler
• TLS fingerprint: Chrome vs. Python requests
• Canvas fingerprint: normal, abnormal oder fixiert
• WebGL: normal, fehlend oder abnormal
Wenn mehrere Dimensionen abnormal erscheinen, ist es in der Regel sicher, den Traffic als automatisiert zu klassifizieren.
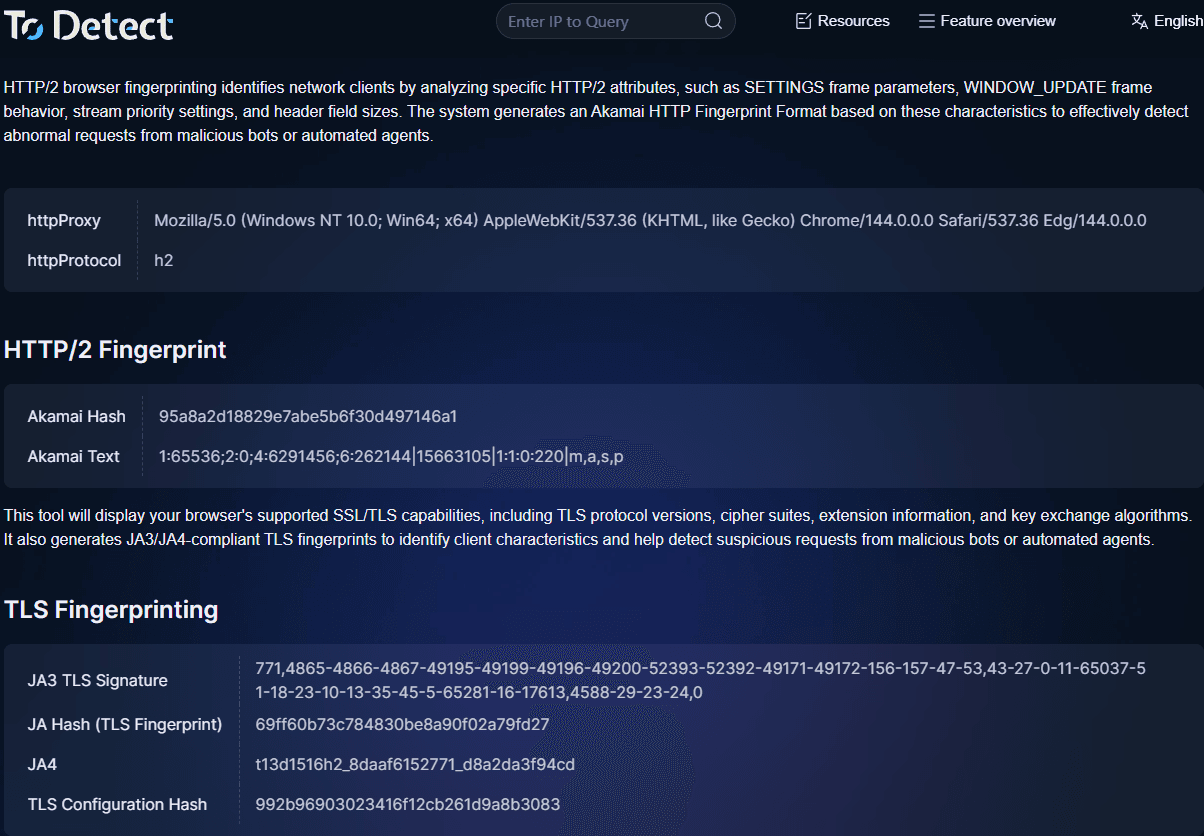
3. Wie TLS fingerprint schnell prüfen
Beim Debuggen oder Analysieren von Traffic können Sie das ToDetect fingerprint Prüfwerkzeug verwenden, um:
• TLS fingerprint anzeigen
• HTTP2 fingerprint analysieren
• Browser fingerprint Eigenschaften erkennen
• Feststellen, ob die Umgebung automatisiert ist
Dies ist bei der Fehlerbehebung sehr nützlich, zum Beispiel:
• Warum bestimmte Anfragen durch Risikokontrolle blockiert werden
• Wo das Automatisierungsskript enttarnt wird
• Ob das fingerprint zu einem echten Browser passt
4. Praktische Hinweise: wie man ein effektives, auf fingerprint basierendes Risikokontrollsystem aufbaut
Ebene 1: Grundlegende Traffic-Identifikation (schnelles Filtern)
Ziel dieser Ebene ist nicht die präzise Identifikation, sondern das schnelle Filtern offensichtlich abnormalen Traffics und die Entlastung nachgelagerter Systeme. Häufige Strategien umfassen:
1) IP- und Anfrageraten-Kontrolle
Rate-Limiting für einzelne IPs, Erkennung hoher Parallelität im selben Subnetz und Kennzeichnung von Rechenzentrums-IPs. Zum Beispiel:
Normale Nutzer: 10–30 Anfragen pro Minute
Abnorme Skripte: Hunderte oder sogar Tausende Anfragen pro Minute
In solchen Fällen können Sie direkt Rate-Limiting, Slider-Verifizierung oder temporäre Sperren auslösen.
2) User-Agent und grundlegende Header-Prüfungen
Prüfen Sie auf offensichtlich unplausible Situationen, wie leere UA-Strings, UA nicht passend zur Plattform oder fehlende kritische Header.
Zum Beispiel: Wenn die UA angibt, Chrome zu sein, aber wichtige Header wie sec-ch-ua oder accept-language fehlen, stammt die Anfrage wahrscheinlich von einem Skript.
Diese Ebene zeichnet sich durch einfache Implementierung, geringen Performance-Overhead aus und dient als erste Filterbarriere.
Ebene 2: Identifikation auf fingerprint-Ebene (Kernschicht der Risikokontrolle)
1) TLS Fingerprinting: Überprüfung der Client-Authentizität
Verwenden Sie JA3, JA4 und ähnliche Methoden, um eine TLS fingerprint Datenbank echter Browser aufzubauen und gängige fingerprint von Automatisierungs-Frameworks zu markieren.
Häufige Anomalien: Die UA behauptet, Chrome zu sein, aber das TLS fingerprint entspricht Python requests; dasselbe Konto ändert häufig sein TLS fingerprint; oder große Mengen von Anfragen teilen dasselbe abnorme fingerprint.
Solcher Traffic kann herabgestuft, mit zusätzlicher Verifizierung herausgefordert oder in eine Risiko-Warteschlange eingereiht werden.
2) HTTP2/TLS fingerprint Erkennung: Fake-Browser identifizieren
Viele Automatisierungstools zeigen auf der HTTP2-Ebene Schwächen, wie Frame-Sequenzen, die nicht zu echten Browsern passen, abnorme Header-Reihenfolgen oder fehlende Prioritätseinstellungen—dies sind typische Automatisierungsmerkmale.
Diese Ebene kann in der Regel identifizieren:
• Headless-Browser
• Automatisierungs-Frameworks
• Crawler, die Browser-Protokoll-Stacks simulieren
Ebene 3: Verhaltensanalyse (finale Entscheidungsschicht)
Auch wenn das fingerprint normal aussieht, bedeutet das nicht unbedingt, dass der Nutzer real ist.
Viele Automatisierungstools können inzwischen Browser fingerprint, TLS fingerprint simulieren oder Residential Proxies verwenden.
Daher muss die finale Ebene eine Verhaltensanalyse enthalten. Häufige Dimensionen umfassen:
1) Zugriffsweg
Echte Nutzer: Startseite → Listen-Seite → Detail-Seite → Login
Crawler: greifen ohne Navigationspfad direkt auf große Mengen von Detail-Seiten zu.
2) Verweildauer und Bedienrhythmus
Echte Nutzer: Verweildauer schwankt, Bedienungen sind unregelmäßig.
Skripte: feste Intervalle, übermäßig schnelle Aktionen.
Zum Beispiel: einen Button alle 2 Sekunden für 100 aufeinanderfolgende Anfragen ohne Pausen klicken, kann allgemein als Automatisierung klassifiziert werden.
Zusammenfassung
Anti-Scraping und Risikokontrolle sind nicht mehr so einfach wie IPs zu blockieren oder Captchas zu ändern. Automatisierungstools können auf der Oberfläche wie echte Nutzer aussehen, hinterlassen jedoch weiterhin Spuren in zugrunde liegenden Protokollen und der Konsistenz der Umgebung.
In realen Projekten müssen Sie nicht sofort ein komplexes System aufbauen. Ein praktikabler Ansatz ist, mit grundlegenden Regeln und Browser Fingerprinting zu beginnen und anschließend TLS Fingerprinting als Kern-Identifikationsschicht einzuführen.
Sie können auch Tools wie den ToDetect fingerprint Checker verwenden, um das TLS fingerprint und die Browser-Eigenschaften der aktuellen Umgebung schnell anzusehen, was die Fehlersuche deutlich erleichtert.
 AD
AD

