Cómo detectar tráfico malicioso mediante HTTP2/TLS Fingerprinting
En las prácticas diarias de control de riesgos y anti‑scraping, los equipos suelen encontrarse con un problema: el bloqueo tradicional de IP y la identificación por UA ya no son suficientes.
Por eso, en los últimos dos años, cada vez más equipos de seguridad han empezado a prestar atención a una dirección técnica—identificación de fingerprint HTTP2/TLS.
A continuación, hablemos de cómo usar fingerprints TLS para identificar tráfico anómalo y rastreadores automatizados, y cómo implementar este enfoque en escenarios empresariales reales.

1. El papel de detección de fingerprint HTTP2/TLS en el anti‑scraping
Muchas herramientas de automatización pueden disfrazarse bien en la capa HTTP, pero quedan expuestas con la detección de fingerprint HTTP2/TLS.
La razón es sencilla: simular un navegador es fácil, pero simular la pila de red subyacente es difícil. Los navegadores reales en HTTP/2 suelen tener:
• Secuencias de tramas específicas
• Configuraciones de prioridad fijas
• Orden específico de encabezados
Las herramientas de automatización, por otro lado, suelen usar librerías por defecto, secuencias de tramas anómalas o órdenes de encabezados que no coinciden con los de navegadores reales—todo esto genera fingerprints HTTP2 anómalos.
En escenarios empresariales reales, muchos equipos combinan TLS Fingerprinting con la detección de fingerprint HTTP2, y añaden comprobaciones de fingerprint de navegador y análisis de comportamiento para formar un sistema de identificación multicapa.
2. Cómo utilizar fingerprints TLS para identificar rastreadores automatizados
Paso 1: recopilar fingerprints TLS de usuarios normales
Primero, recopila datos de acceso de usuarios reales—por ejemplo, fingerprints JA3 de las últimas versiones de Chrome, características TLS de Safari y diferencias entre sistemas operativos—para construir una base de datos de fingerprint de referencia.
Paso 2: identificar fingerprints TLS anómalos
Cuando llega una nueva solicitud: extrae el fingerprint TLS, compáralo con la base de datos de fingerprint y determina si es un cliente anómalo.
Las anomalías comunes incluyen:
• Fingerprints TLS no de navegador
• Fingerprints de frameworks de rastreadores conocidos
• Solicitudes con fingerprints que cambian con frecuencia
Todas estas pueden colocarse directamente en una cola de riesgo.
Paso 3: combinar con detección de fingerprint de navegador
TLS Fingerprinting por sí solo es potente, pero se recomienda combinarlo con la detección de fingerprint de navegador. Por ejemplo:
• Usuarios reales vs. rastreadores automatizados
• Fingerprint TLS: Chrome vs. Python requests
• Canvas fingerprint: normal, anómalo o fijo
• WebGL: normal, ausente o anómalo
Cuando varias dimensiones aparecen anómalas, normalmente es seguro clasificar el tráfico como automatizado.
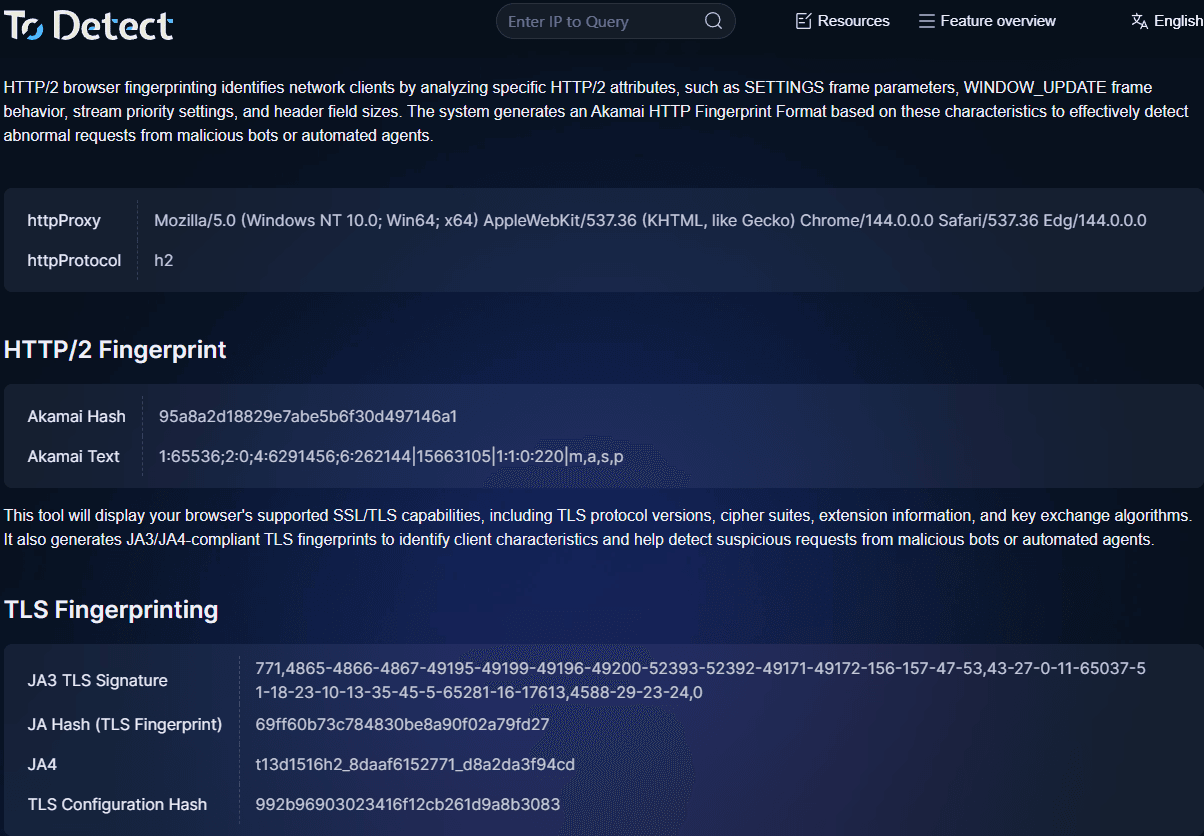
3. Cómo comprobar rápidamente fingerprints TLS
Al depurar o analizar tráfico, puedes usar la herramienta de comprobación de fingerprint de ToDetect para:
• Ver fingerprints TLS
• Analizar fingerprints HTTP2
• Detectar características de fingerprint de navegador
• Determinar si el entorno está automatizado
Esto es muy útil durante la resolución de problemas, por ejemplo:
• Por qué ciertas solicitudes son bloqueadas por el control de riesgos
• Dónde se expone el script de automatización
• Si el fingerprint coincide con un navegador real
4. Consejos prácticos: cómo construir un sistema de control de riesgos eficaz basado en fingerprint
Capa 1: identificación básica de tráfico (filtrado rápido)
El objetivo de esta capa no es la identificación precisa, sino filtrar rápidamente el tráfico obviamente anómalo y reducir la carga de los sistemas posteriores. Las estrategias comunes incluyen:
1) Control de IP y frecuencia de solicitudes
Limitación de tasa por IP única, detección de alta concurrencia dentro de la misma subred y etiquetado de IP de centros de datos. Por ejemplo:
Usuarios normales: 10–30 solicitudes por minuto
Scripts anómalos: cientos o incluso miles de solicitudes por minuto
En estos casos, puedes activar directamente limitación de tasa, verificación con deslizador o bloqueos temporales.
2) Comprobaciones de User-Agent y headers básicos
Comprueba situaciones claramente irrazonables, como cadenas UA vacías, UA que no coincide con la plataforma o ausencia de headers críticos.
Por ejemplo: si la UA afirma ser Chrome pero carece de headers clave como sec-ch-ua o accept-language, es probable que la solicitud provenga de un script.
Esta capa se caracteriza por una implementación sencilla, bajo costo de rendimiento y sirve como la primera barrera de filtrado.
Capa 2: identificación a nivel de fingerprint (capa central de control de riesgos)
1) TLS Fingerprinting: verificar la autenticidad del cliente
Usa JA3, JA4 y métodos similares para construir una base de datos de fingerprint TLS de navegadores reales y etiquetar fingerprints comunes de frameworks de automatización.
Anomalías comunes: la UA dice ser Chrome pero el fingerprint TLS coincide con Python requests; la misma cuenta cambia con frecuencia los fingerprints TLS; o grandes volúmenes de solicitudes comparten el mismo fingerprint anómalo.
Dicho tráfico puede degradarse, someterse a verificaciones adicionales o colocarse en una cola de riesgo.
2) Detección de fingerprint HTTP2/TLS: identificar navegadores falsos
Muchas herramientas de automatización revelan fallos en la capa HTTP2, como secuencias de tramas que no coinciden con navegadores reales, orden de encabezados anómalo o ausencia de configuraciones de prioridad—estas son características típicas de automatización.
Esta capa suele identificar:
• Navegadores Headless
• Frameworks de automatización
• Rastreadores que simulan pilas de protocolos de navegador
Capa 3: análisis de comportamiento (capa de decisión final)
Incluso si el fingerprint parece normal, no necesariamente significa que el usuario sea real.
Muchas herramientas de automatización ahora pueden simular fingerprints de navegador, fingerprints TLS o usar Proxy residenciales.
Por lo tanto, la capa final debe incluir análisis de comportamiento. Las dimensiones comunes incluyen:
1) Ruta de acceso
Usuarios reales: página de inicio → página de lista → página de detalle → inicio de sesión
Rastreadores: acceden directamente a grandes cantidades de páginas de detalle sin una ruta de navegación.
2) Tiempo de permanencia y ritmo de operación
Usuarios reales: el tiempo de permanencia fluctúa, las operaciones son irregulares.
Scripts: intervalos fijos, acciones excesivamente rápidas.
Por ejemplo: hacer clic en un botón cada 2 segundos durante 100 solicitudes consecutivas sin pausas generalmente puede clasificarse como automatización.
Resumen
El anti‑scraping y el control de riesgos ya no son tan simples como bloquear IPs o cambiar captchas. Las herramientas de automatización pueden parecer usuarios reales a nivel superficial, pero aún dejan huellas en los protocolos subyacentes y en la consistencia del entorno.
En proyectos reales, no es necesario construir un sistema complejo de una sola vez. Un enfoque más práctico es comenzar con reglas básicas y Fingerprinting de navegador, luego introducir TLS Fingerprinting como capa central de identificación.
También puedes usar herramientas como el comprobador de fingerprint de ToDetect para ver rápidamente el fingerprint TLS y las características de navegador del entorno actual, lo que hace mucho más fácil la resolución de problemas.
 AD
AD

