HTTP2/TLS フィンガープリンティングで悪意のあるトラフィックを検出する方法
日々のリスクコントロールやアンチスクレイピングの実務では、チームはしばしば次の問題に直面します:従来のIPブロックやUA識別だけでは不十分になっています。
そのため、ここ2年ほどで、より多くのセキュリティチームが HTTP2/TLS フィンガープリント識別という技術的方向性に注目し始めています。
次に、TLS フィンガープリントを用いて異常トラフィックや自動化クローラーを識別する方法、および実際の業務シナリオでの実装方法について説明します。

1. アンチスクレイピングにおける HTTP2/TLS フィンガープリント検出 の役割
多くの自動化ツールは HTTP レイヤーでは巧妙に偽装できますが、HTTP2/TLS フィンガープリント検出によって容易に露見します。
理由は単純です。ブラウザーの見た目を模倣するのは容易でも、基盤となるネットワークスタックを再現するのは難しいからです。実際のブラウザーは HTTP/2 で一般的に次の特徴を持ちます:
• 特定のフレームシーケンス
• 固定化された優先度設定
• 特定のヘッダー順序
一方で自動化ツールは、デフォルトのライブラリを用いたり、異常なフレームシーケンスや実ブラウザーと一致しないヘッダー順序を示すことが多く、これらが異常な HTTP2 フィンガープリントを生み出します。
実際のビジネスシナリオでは、多くのチームが TLS フィンガープリントと HTTP2 フィンガープリント検出を組み合わせ、さらにブラウザーフィンガープリントのチェックや行動分析を加えて、多層的な識別システムを構築しています。
2. TLS フィンガープリントで自動化クローラーを識別する方法
ステップ 1:正常ユーザーの TLS フィンガープリントを収集
まず、実ユーザーのアクセスデータを収集します。例えば、最新の Chrome バージョンの JA3 フィンガープリント、Safari の TLS 特性、OS ごとの違いなどを集め、ベースラインとなるフィンガープリントデータベースを構築します。
ステップ 2:異常な TLS フィンガープリントを特定
新しいリクエストが到着したら、TLS フィンガープリントを抽出し、フィンガープリントデータベースと照合して、異常なクライアントかどうかを判定します。
よくある異常例:
• ブラウザーではない TLS フィンガープリント
• 既知のクローラーフレームワークのフィンガープリント
• フィンガープリントが頻繁に変化するリクエスト
これらはすべて、直接リスクキューに入れることができます。
ステップ 3:ブラウザーフィンガープリント検出と組み合わせる
TLS フィンガープリンティング単体でも強力ですが、ブラウザーフィンガープリント検出と組み合わせることを推奨します。例えば:
• 実ユーザー vs. 自動化クローラー
• TLS フィンガープリント:Chrome vs. Python requests
• Canvas フィンガープリント:正常 / 異常 / 固定
• WebGL:正常 / 欠落 / 異常
複数の次元で異常が見られる場合、そのトラフィックを自動化と分類しても通常は安全です。
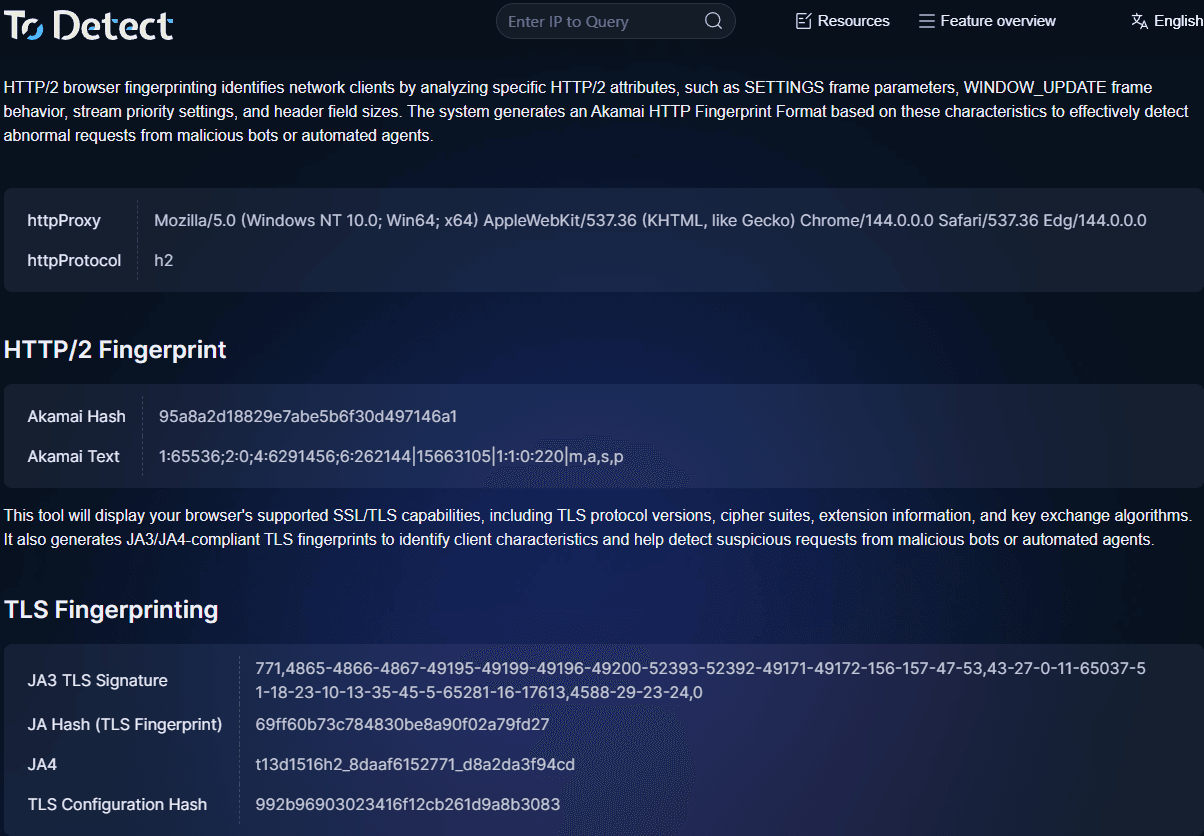
3. TLS フィンガープリントをすばやく確認する方法
デバッグやトラフィック分析の際は、ToDetect のフィンガープリントチェックツールを利用して次のことが行えます:
• TLS フィンガープリントを表示
• HTTP2 フィンガープリントを分析
• ブラウザーフィンガープリントの特徴を検出
• 環境が自動化されているかを判定
これはトラブルシューティング時に非常に有用です。例えば:
• 一部のリクエストがリスクコントロールでブロックされる理由
• 自動化スクリプトがどこで露見しているか
• フィンガープリントが実ブラウザーと一致しているか
4. 実践的アドバイス:効果的なフィンガープリントベースのリスクコントロールシステムの構築方法
レイヤー1:基本的なトラフィック識別(高速フィルタリング)
このレイヤーの目的は精緻な識別ではなく、明らかに異常なトラフィックを素早くふるい分け、下流システムの負荷を軽減することです。一般的な戦略は次のとおりです:
1) IP とリクエスト頻度の制御
単一IPのレート制限、同一サブネット内の高並行アクセスの検知、データセンターIPのタグ付けなど。例えば:
通常のユーザー:1分あたり10〜30リクエスト
異常なスクリプト:1分あたり数百〜数千リクエスト
このような場合、レート制限、スライダー認証、一時的なブロックを直接発動できます。
2) User-Agent と基本ヘッダーのチェック
UA が空である、プラットフォームと一致しない、重要なヘッダーが欠落しているなど、明らかに不合理な状況をチェックします。
例:UA が Chrome を名乗っているのに、sec-ch-ua や accept-language といった重要ヘッダーがない場合、そのリクエストはスクリプト由来の可能性が高いです。
このレイヤーは実装が簡単でオーバーヘッドが小さく、最初のフィルタリングの壁として機能します。
レイヤー2:フィンガープリントレベルの識別(中核のリスクコントロール層)
1) TLS フィンガープリンティング:クライアントの真正性を検証
JA3、JA4 などの手法を用いて、実ブラウザーの TLS フィンガープリントデータベースを構築し、一般的な自動化フレームワークのフィンガープリントにタグ付けします。
よくある異常例:UA は Chrome と主張しているが TLS フィンガープリントが Python requests と一致する、同一アカウントで TLS フィンガープリントが頻繁に変わる、大量のリクエストが同一の異常フィンガープリントを共有している、など。
そのようなトラフィックは、優先度を下げる、追加認証でチャレンジする、リスクキューに入れる、といった対応が可能です。
2) HTTP2/TLS フィンガープリント検出:偽ブラウザーの識別
多くの自動化ツールは HTTP2 レイヤーで欠点が露呈します。実ブラウザーと一致しないフレームシーケンス、異常なヘッダー順序、優先度設定の欠如などは、典型的な自動化の特徴です。
このレイヤーでは通常、次のものを識別できます:
• Headless ブラウザー
• 自動化フレームワーク
• ブラウザーのプロトコルスタックを模倣するクローラー
レイヤー3:行動分析(最終判断レイヤー)
フィンガープリントが正常に見えても、必ずしも実ユーザーとは限りません。
現在では多くの自動化ツールが、ブラウザーフィンガープリントや TLS フィンガープリントを模倣したり、レジデンシャル Proxy を使用できます。
したがって、最終レイヤーには行動分析を含める必要があります。一般的な観点は次のとおりです:
1) アクセス経路
実ユーザー:ホーム → 一覧ページ → 詳細ページ → ログイン
クローラー:遷移経路なしに大量の詳細ページへ直接アクセス
2) 滞在時間と操作リズム
実ユーザー:滞在時間は揺らぎがあり、操作は不規則。
スクリプト:一定間隔、過度に速い操作。
例:2秒ごとにボタンを連続100回クリックするなど、休止のない操作は概ね自動化と分類できます。
まとめ
アンチスクレイピングやリスクコントロールは、IP をブロックしたり CAPTCHA を変えるだけの単純な問題ではありません。自動化ツールは表層では実ユーザーのように見えても、基盤となるプロトコルや環境の一貫性に痕跡を残します。
実プロジェクトでは、複雑なシステムを一度に構築する必要はありません。まず基本ルールとブラウザーフィンガープリンティングから始め、コアの識別レイヤーとして TLS フィンガープリントを導入する方が現実的です。
また、ToDetect のフィンガープリントチェッカーなどのツールを使えば、現在の環境の TLS フィンガープリントやブラウザーの特性を素早く確認でき、トラブルシューティングが大幅に容易になります。
 AD
AD

