HTTP2/TLS Fingerprinting을 사용하여 악성 트래픽을 탐지하는 방법
일상적인 리스크 통제 및 반스크래핑 실무에서 팀은 종종 한 가지 문제에 직면합니다: 기존의 IP 차단과 UA 식별만으로는 더 이상 충분하지 않습니다.
이 때문에 지난 2년 동안 점점 더 많은 보안 팀이 하나의 기술 방향—HTTP2/TLS fingerprint 식별—에 주목하기 시작했습니다.
다음으로 TLS fingerprints를 사용해 이상 트래픽과 자동화 크롤러를 식별하는 방법, 그리고 이를 실제 비즈니스 시나리오에 적용하는 방법을 살펴보겠습니다.

1. 반스크래핑에서 HTTP2/TLS fingerprint detection의 역할
많은 자동화 도구는 HTTP 레이어에서 자신을 잘 위장할 수 있지만, HTTP2/TLS fingerprint detection에 의해 쉽게 드러납니다.
이유는 단순합니다: 브라우저를 모방하는 것은 쉽지만, 하위 네트워크 스택을 모방하는 것은 어렵습니다. 실제 브라우저는 HTTP/2에서 일반적으로 다음을 갖습니다:
• 특정 프레임 시퀀스
• 고정된 우선순위 설정
• 특정 헤더 순서
반면 자동화 도구는 기본 라이브러리 사용, 비정상적인 프레임 시퀀스, 실제 브라우저와 일치하지 않는 헤더 순서 등을 보이며—이 모두가 비정상적인 HTTP2 fingerprints를 생성합니다.
실제 비즈니스 시나리오에서 많은 팀은 TLS Fingerprinting과 HTTP2 fingerprint detection을 결합한 다음 브라우저 fingerprint 점검과 행위 분석을 추가해 다층 식별 시스템을 구성합니다.
2. TLS fingerprints를 사용하여 자동화 크롤러를 식별하는 방법
Step 1: 정상 사용자의 TLS fingerprints 수집
먼저 실제 사용자의 접근 데이터를 수집합니다—예: 최신 Chrome 버전의 JA3 fingerprints, Safari의 TLS 특성, 운영체제별 차이—를 기반으로 기준 fingerprint 데이터베이스를 구축합니다.
Step 2: 비정상 TLS fingerprints 식별
새로운 요청이 도착하면: TLS fingerprint를 추출하여 fingerprint 데이터베이스와 매칭하고, 비정상 클라이언트인지 판단합니다.
일반적인 이상 징후는 다음과 같습니다:
• 브라우저가 아닌 TLS fingerprints
• 알려진 크롤러 프레임워크 fingerprints
• fingerprints가 자주 변하는 요청
이들은 모두 직접 리스크 큐에 넣을 수 있습니다.
Step 3: 브라우저 fingerprint detection과 결합
TLS Fingerprinting만으로도 강력하지만, 브라우저 fingerprint detection과 결합할 것을 권장합니다. 예를 들면:
• 실제 사용자 vs. 자동화 크롤러
• TLS fingerprint: Chrome vs. Python requests
• Canvas fingerprint: 정상, 비정상, 또는 고정
• WebGL: 정상, 누락, 또는 비정상
여러 차원에서 이상이 나타나면, 해당 트래픽을 자동화로 분류하는 것이 대체로 안전합니다.
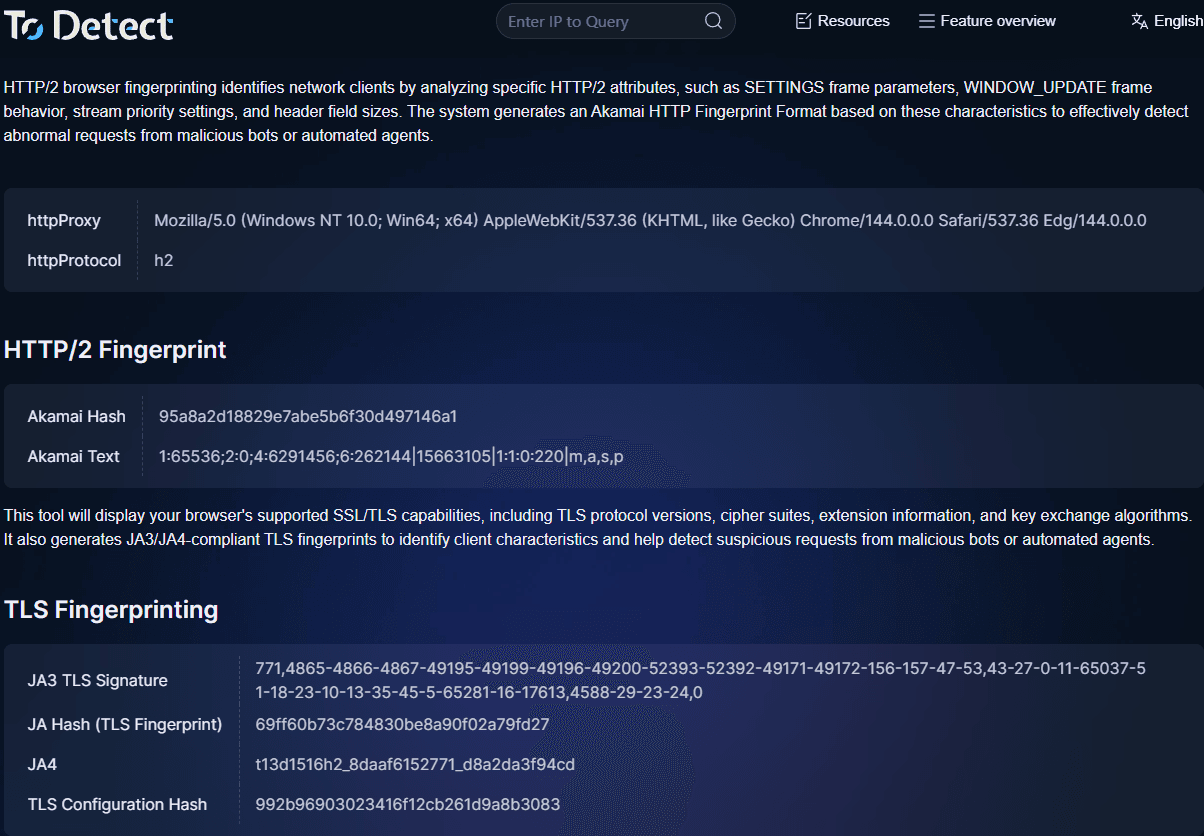
3. 빠르게 확인하는 방법: TLS fingerprints
디버깅이나 트래픽 분석 시, ToDetect의 fingerprint 확인 도구를 통해 다음을 수행할 수 있습니다:
• TLS fingerprints 보기
• HTTP2 fingerprints 분석
• 브라우저 fingerprint 특성 탐지
• 환경이 자동화인지 여부 판단
이는 트러블슈팅 과정에서 매우 유용하며, 예를 들어:
• 특정 요청이 리스크 통제에 의해 차단되는 이유
• 자동화 스크립트가 드러나는 지점
• fingerprint가 실제 브라우저와 일치하는지 여부
4. 실용 조언: 효과적인 fingerprint 기반 리스크 통제 시스템을 구축하는 방법
Layer 1: 기본 트래픽 식별(신속 필터링)
이 레이어의 목표는 정밀 식별이 아니라, 명백히 비정상적인 트래픽을 신속히 걸러내어 다운스트림 시스템의 부하를 줄이는 것입니다. 일반적인 전략은 다음과 같습니다:
1) IP 및 요청 빈도 제어
단일 IP 레이트 리미팅, 동일 서브넷 내 고동시성 탐지, 데이터센터 IP 태깅. 예:
일반 사용자: 분당 10–30 요청
비정상 스크립트: 분당 수백 또는 수천 요청
이러한 경우 레이트 리미팅, 슬라이더 검증, 또는 일시적 차단을 직접 트리거할 수 있습니다.
2) User-Agent 및 기본 헤더 점검
UA 문자열이 비어 있음, 플랫폼과 맞지 않는 UA, 필수 헤더 누락 등 명백히 불합리한 상황을 점검합니다.
예: UA가 Chrome이라고 주장하지만 sec-ch-ua 또는 accept-language와 같은 핵심 헤더가 없으면, 해당 요청은 스크립트일 가능성이 높습니다.
이 레이어는 구현이 간단하고, 성능 오버헤드가 낮으며, 첫 번째 필터링 장벽 역할을 합니다.
Layer 2: Fingerprint 레벨 식별(코어 리스크 통제 레이어)
1) TLS Fingerprinting: 클라이언트 진위 검증
JA3, JA4 등의 방법을 사용하여 실제 브라우저의 TLS fingerprint 데이터베이스를 구축하고, 일반적인 자동화 프레임워크 fingerprints를 태깅합니다.
일반적인 이상: UA는 Chrome이라고 하지만 TLS fingerprint가 Python requests와 일치함; 동일 계정의 TLS fingerprints가 자주 변경됨; 대량의 요청이 동일한 비정상 fingerprint를 공유함.
이러한 트래픽은 등급을 낮추거나 추가 검증으로 챌린지하거나 리스크 큐에 넣을 수 있습니다.
2) HTTP2/TLS fingerprint detection: 가짜 브라우저 식별
많은 자동화 도구는 HTTP2 레이어에서 결함을 드러냅니다. 예를 들어, 실제 브라우저와 일치하지 않는 프레임 시퀀스, 비정상적인 헤더 순서, 우선순위 설정 누락 등—이는 전형적인 자동화 특성입니다.
이 레이어는 보통 다음을 식별할 수 있습니다:
• Headless 브라우저
• 자동화 프레임워크
• 브라우저 프로토콜 스택을 모사하는 크롤러
Layer 3: 행위 분석(최종 의사결정 레이어)
fingerprint가 정상처럼 보여도, 사용자가 실제라는 의미는 아닙니다.
현재 많은 자동화 도구가 브라우저 fingerprints, TLS fingerprints를 모사하거나, 주거용 proxies를 사용할 수 있습니다.
따라서 마지막 레이어에는 행위 분석이 반드시 포함되어야 합니다. 일반적인 차원은 다음과 같습니다:
1) 접근 경로
실제 사용자: 홈 → 목록 페이지 → 상세 페이지 → 로그인
크롤러: 네비게이션 경로 없이 다수의 상세 페이지를 직접 접근.
2) 체류 시간과 동작 리듬
실제 사용자: 체류 시간이 변동하고, 동작이 불규칙함.
스크립트: 고정된 간격, 과도하게 빠른 동작.
예: 2초마다 버튼을 클릭해 100건의 연속 요청을 중단 없이 수행하는 경우는 일반적으로 자동화로 분류할 수 있습니다.
요약
반스크래핑과 리스크 통제는 더 이상 IP를 차단하거나 캡차를 바꾸는 것만큼 간단하지 않습니다. 자동화 도구는 표면적으로 실제 사용자처럼 보일 수 있지만, 하위 프로토콜과 환경 일관성에서 흔적을 남깁니다.
현실 프로젝트에서는 복잡한 시스템을 한 번에 구축할 필요가 없습니다. 보다 실용적인 접근은 기본 규칙과 브라우저 Fingerprinting부터 시작하고, TLS Fingerprinting을 핵심 식별 레이어로 도입하는 것입니다.
또한 ToDetect의 fingerprint 검사기와 같은 도구를 사용하여 현재 환경의 TLS fingerprint와 브라우저 특성을 빠르게 확인함으로써 트러블슈팅을 훨씬 수월하게 할 수 있습니다.
 AD
AD

