วิธีตรวจจับทราฟฟิกที่เป็นอันตรายด้วย HTTP2/TLS Fingerprinting
ในการปฏิบัติด้านการควบคุมความเสี่ยงและการต่อต้านการขูดข้อมูลในแต่ละวัน ทีมมักพบปัญหา: การบล็อก IP แบบดั้งเดิมและการระบุ UA ไม่เพียงพออีกต่อไป.
ด้วยเหตุนี้ ตลอดสองปีที่ผ่านมา ทีมรักษาความปลอดภัยจำนวนมากขึ้นได้เริ่มให้ความสนใจแนวทางทางเทคนิค—การระบุ HTTP2/TLS fingerprint.
ถัดไป มาพูดถึงวิธีใช้ TLS fingerprints เพื่อระบุทราฟฟิกที่ผิดปกติและครอว์เลอร์อัตโนมัติ และวิธีนำแนวทางนี้ไปใช้ในสถานการณ์ธุรกิจจริง.

1. บทบาทของ การตรวจจับ HTTP2/TLS fingerprint ในการต่อต้านการขูดข้อมูล
เครื่องมืออัตโนมัติจำนวนมากสามารถปลอมตัวได้ดีในเลเยอร์ HTTP แต่ถูกเปิดโปงได้ง่ายโดยการตรวจจับ HTTP2/TLS fingerprint.
เหตุผลนั้นง่าย: การจำลองเบราว์เซอร์ทำได้ง่าย แต่การจำลองสแต็กเครือข่ายชั้นล่างทำได้ยาก เบราว์เซอร์จริงใน HTTP/2 โดยทั่วไปมี:
• ลำดับเฟรมเฉพาะ
• การตั้งค่าลำดับความสำคัญที่คงที่
• การเรียงลำดับ header เฉพาะ
ในทางกลับกัน เครื่องมืออัตโนมัติมักใช้ไลบรารีเริ่มต้น ลำดับเฟรมที่ผิดปกติ หรือการเรียงลำดับ header ที่ไม่ตรงกับเบราว์เซอร์จริง—ทั้งหมดนี้สร้าง HTTP2 fingerprints ที่ผิดปกติ.
ในสถานการณ์ธุรกิจจริง หลายทีมผสาน TLS fingerprinting กับการตรวจจับ HTTP2 fingerprint แล้วเพิ่มการตรวจสอบ browser fingerprint และการวิเคราะห์พฤติกรรม เพื่อสร้างระบบการระบุหลายชั้น.
2. วิธีใช้ TLS fingerprints เพื่อระบุครอว์เลอร์อัตโนมัติ
ขั้นตอนที่ 1: รวบรวม TLS fingerprints ของผู้ใช้ปกติ
อันดับแรก รวบรวมข้อมูลการเข้าถึงจากผู้ใช้จริง—เช่น JA3 fingerprints ของ Chrome เวอร์ชันล่าสุด ลักษณะ TLS ของ Safari และความแตกต่างข้ามระบบปฏิบัติการ—เพื่อสร้างฐานข้อมูล fingerprint มาตรฐาน.
ขั้นตอนที่ 2: ระบุ TLS fingerprints ที่ผิดปกติ
เมื่อมีคำขอใหม่เข้ามา: แยก TLS fingerprint จับคู่กับฐานข้อมูล fingerprint แล้วตัดสินว่าเป็นไคลเอนต์ที่ผิดปกติหรือไม่.
ความผิดปกติที่พบบ่อย ได้แก่:
• TLS fingerprints ที่ไม่ใช่เบราว์เซอร์
• fingerprints ของเฟรมเวิร์กครอว์เลอร์ที่รู้จัก
• คำขอที่ fingerprints เปลี่ยนบ่อย
สิ่งเหล่านี้สามารถนำไปใส่คิวความเสี่ยงได้โดยตรง.
ขั้นตอนที่ 3: ผสานกับการตรวจจับ browser fingerprint
การทำ TLS fingerprinting เพียงอย่างเดียวทรงพลัง แต่แนะนำให้ผสานกับการตรวจจับ browser fingerprint ตัวอย่างเช่น:
• ผู้ใช้จริง vs ครอว์เลอร์อัตโนมัติ
• TLS fingerprint: Chrome vs. Python requests
• Canvas fingerprint: ปกติ ผิดปกติ หรือคงที่
• WebGL: ปกติ ไม่มี หรือผิดปกติ
เมื่อหลายมิติปรากฏว่าผิดปกติ โดยทั่วไปสามารถจำแนกทราฟฟิกว่าเป็นอัตโนมัติได้อย่างปลอดภัย.
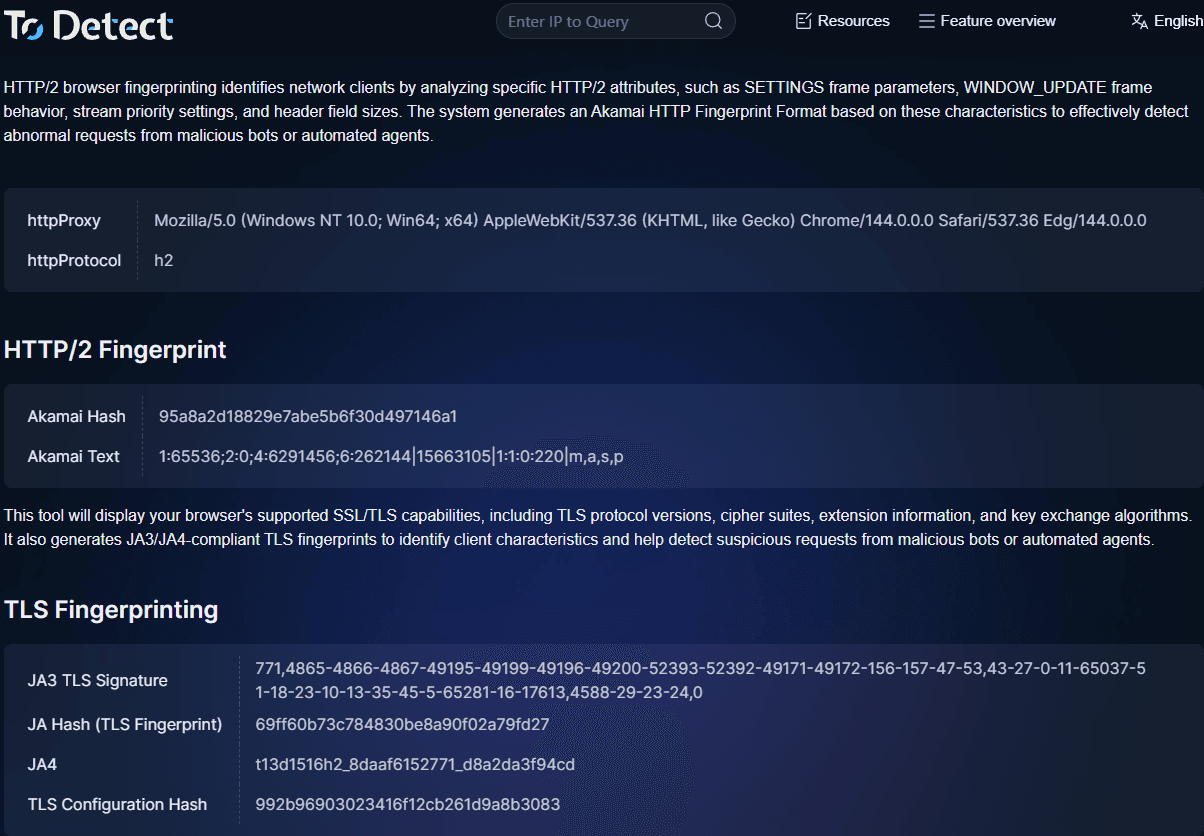
3. วิธีตรวจสอบอย่างรวดเร็ว TLS fingerprints
เมื่อดีบักหรือวิเคราะห์ทราฟฟิก คุณสามารถใช้เครื่องมือตรวจสอบ fingerprint ของ ToDetect เพื่อ:
• ดู TLS fingerprints
• วิเคราะห์ HTTP2 fingerprints
• ตรวจจับลักษณะของ browser fingerprint
• ระบุว่าสภาพแวดล้อมเป็นอัตโนมัติหรือไม่
สิ่งนี้มีประโยชน์มากระหว่างการแก้ไขปัญหา เช่น:
• เหตุใดคำขอบางอย่างจึงถูกบล็อกโดยระบบควบคุมความเสี่ยง
• สคริปต์อัตโนมัติเปิดโปงที่จุดใด
• fingerprint ตรงกับเบราว์เซอร์จริงหรือไม่
4. คำแนะนำเชิงปฏิบัติ: วิธีสร้างระบบควบคุมความเสี่ยงที่มีประสิทธิภาพโดยอิง fingerprint
เลเยอร์ที่ 1: การระบุทราฟฟิกพื้นฐาน (การกรองอย่างรวดเร็ว)
เป้าหมายของเลเยอร์นี้ไม่ใช่การระบุอย่างแม่นยำ แต่เพื่อกรองทราฟฟิกที่ผิดปกติอย่างเห็นได้ชัดอย่างรวดเร็วและลดภาระของระบบปลายทาง กลยุทธ์ที่พบบ่อย ได้แก่:
1) การควบคุม IP และความถี่คำขอ
การจำกัดอัตราต่อ IP เดียว การตรวจจับความหนาแน่นสูงภายในซับเน็ตเดียวกัน และการติดแท็ก IP ศูนย์ข้อมูล ตัวอย่างเช่น:
ผู้ใช้ปกติ: 10–30 คำขอต่อนาที
สคริปต์ผิดปกติ: หลายร้อยหรือหลายพันคำขอต่อนาที
ในกรณีเช่นนี้ คุณสามารถทริกเกอร์การจำกัดอัตรา การยืนยันด้วยสไลเดอร์ หรือแบนชั่วคราวได้โดยตรง.
2) User-Agent และการตรวจสอบ header ขั้นพื้นฐาน
ตรวจสอบสถานการณ์ที่ไม่สมเหตุสมผลอย่างชัดเจน เช่น สตริง UA ว่าง UA ไม่ตรงกับแพลตฟอร์ม หรือขาด header สำคัญ.
เช่น หาก UA อ้างว่าเป็น Chrome แต่ไม่มี header สำคัญอย่าง sec-ch-ua หรือ accept-language คำขอนั้นน่าจะมาจากสคริปต์.
เลเยอร์นี้มีลักษณะคือใช้งานง่าย ภาระด้านประสิทธิภาพต่ำ และทำหน้าที่เป็นด่านกรองแรก.
เลเยอร์ที่ 2: การระบุระดับ fingerprint (ชั้นแกนกลางของการควบคุมความเสี่ยง)
1) TLS fingerprinting: ตรวจสอบความแท้จริงของไคลเอนต์
ใช้ JA3, JA4 และวิธีการที่คล้ายกันเพื่อสร้างฐานข้อมูล TLS fingerprint ของเบราว์เซอร์จริง และติดแท็ก fingerprints ของเฟรมเวิร์กอัตโนมัติที่พบทั่วไป.
ความผิดปกติที่พบบ่อย: UA อ้างว่าเป็น Chrome แต่ TLS fingerprint ตรงกับ Python requests; บัญชีเดียวเปลี่ยน TLS fingerprints บ่อย; หรือคำขอจำนวนมากใช้ fingerprint ที่ผิดปกติเดียวกัน.
ทราฟฟิกดังกล่าวสามารถลดระดับ ท้าทายด้วยการยืนยันเพิ่มเติม หรือใส่ไว้ในคิวความเสี่ยง.
2) การตรวจจับ HTTP2/TLS fingerprint: ระบุเบราว์เซอร์ปลอม
เครื่องมืออัตโนมัติจำนวนมากเผยให้เห็นข้อบกพร่องที่เลเยอร์ HTTP2 เช่น ลำดับเฟรมที่ไม่ตรงกับเบราว์เซอร์จริง การเรียงลำดับ header ที่ผิดปกติ หรือขาดการตั้งค่าลำดับความสำคัญ—สิ่งเหล่านี้เป็นลักษณะอัตโนมัติทั่วไป.
เลเยอร์นี้มักจะสามารถระบุได้ว่า:
• เบราว์เซอร์แบบ Headless
• เฟรมเวิร์กอัตโนมัติ
• ครอว์เลอร์ที่จำลองสแต็กโปรโตคอลของเบราว์เซอร์
เลเยอร์ที่ 3: การวิเคราะห์พฤติกรรม (ชั้นตัดสินขั้นสุดท้าย)
แม้ fingerprint จะดูปกติ ก็ไม่ได้หมายความว่าผู้ใช้เป็นของจริงเสมอไป.
ขณะนี้เครื่องมืออัตโนมัติหลายตัวสามารถจำลอง browser fingerprints, TLS fingerprints หรือใช้ Residential Proxy ได้.
ดังนั้น เลเยอร์สุดท้ายต้องมีการวิเคราะห์พฤติกรรม มิติที่พบบ่อย ได้แก่:
1) เส้นทางการเข้าถึง
ผู้ใช้จริง: หน้าแรก → หน้ารายการ → หน้ารายละเอียด → เข้าสู่ระบบ
ครอว์เลอร์: เข้าถึงหน้ารายละเอียดจำนวนมากโดยตรงโดยไม่มีเส้นทางนำทาง.
2) เวลาอยู่นิ่งและจังหวะการกระทำ
ผู้ใช้จริง: เวลาอยู่นิ่งผันผวน การกระทำไม่สม่ำเสมอ.
สคริปต์: ระยะเวลาแน่นอน การกระทำเร็วเกินไป.
เช่น คลิกปุ่มทุก 2 วินาทีติดต่อกัน 100 คำขอโดยไม่หยุดพัก โดยทั่วไปสามารถจัดเป็นอัตโนมัติได้.
สรุป
การต่อต้านการขูดข้อมูลและการควบคุมความเสี่ยงไม่ใช่เรื่องง่ายเหมือนการบล็อก IP หรือเปลี่ยนแคปช่าอีกต่อไป เครื่องมืออัตโนมัติอาจดูเหมือนผู้ใช้จริงในระดับผิว แต่ยังคงทิ้งร่องรอยไว้ในโปรโตคอลชั้นล่างและความสอดคล้องของสภาพแวดล้อม.
ในโครงการจริง คุณไม่จำเป็นต้องสร้างระบบที่ซับซ้อนทั้งหมดในครั้งเดียว แนวทางที่ใช้งานได้จริงมากกว่าคือเริ่มจากกฎพื้นฐานและการทำ browser fingerprinting จากนั้นค่อยเพิ่ม TLS fingerprinting เป็นชั้นการระบุแกนกลาง.
คุณยังสามารถใช้เครื่องมืออย่าง ToDetect fingerprint checker เพื่อดู TLS fingerprint และลักษณะของเบราว์เซอร์ของสภาพแวดล้อมปัจจุบันได้อย่างรวดเร็ว ทำให้การแก้ไขปัญหาง่ายขึ้นมาก.
 AD
AD