如何通過HTTP2/TLS指紋識別異常流量?完整思路分享
在日常的風控與反爬實踐中,都會遇到一個問題:傳統的IP封禁和UA識別越來越不夠用了。
這也是為什麼這兩年越來越多安全團隊開始關注一個技術方向——HTTP2/TLS指紋識別。
接下來就和大家聊一聊如何透過 TLS 指紋識別異常流量與自動化爬蟲,以及在實際業務中該如何落地。

一、HTTP2/TLS指紋檢測在反爬中的作用
很多自動化工具在 HTTP 層可以高度偽裝,但在 HTTP2/TLS指紋檢測 中卻容易暴露。
原因很簡單:模擬瀏覽器容易,模擬底層網路棧很難。真實瀏覽器在 HTTP/2 中會有:
• 特定的幀順序
• 固定的優先級設置
• 特定的 Header 排列方式
而自動化工具往往:使用預設庫、幀順序異常、Header 排列不符合真實瀏覽器,這些都會形成異常的 HTTP2 指紋。
在實際業務中,很多團隊會做:TLS 指紋識別 + HTTP2 指紋檢測,再結合瀏覽器指紋檢測,最後疊加行為分析,形成一個多層識別體系。
二、如何用 TLS 指紋識別自動化爬蟲
第一步:收集正常用戶的 TLS 指紋。
先統計真實用戶的訪問數據,例如:Chrome 最新版的 JA3 指紋、Safari 的 TLS 特徵、不同系統下的差異,建立一個正常指紋庫。
第二步:識別異常 TLS 指紋
當新請求進入時:提取 TLS 指紋、與指紋庫進行匹配、判斷是否為異常客戶端。
常見異常包括:
• 非瀏覽器 TLS 指紋
• 已知爬蟲框架指紋
• 指紋頻繁變化的請求
這些都可以直接進入風險隊列。
第三步:結合瀏覽器指紋檢測
單純的 TLS 指紋識別雖然強大,但更推薦與瀏覽器指紋檢測結合使用。例如:
• 項目真人用戶 自動化爬蟲
• TLS 指紋 Chrome Python requests
• Canvas 指紋正常、異常或固定
• WebGL 正常、缺失或異常
當多個維度都異常時,基本可以確定是自動化流量。
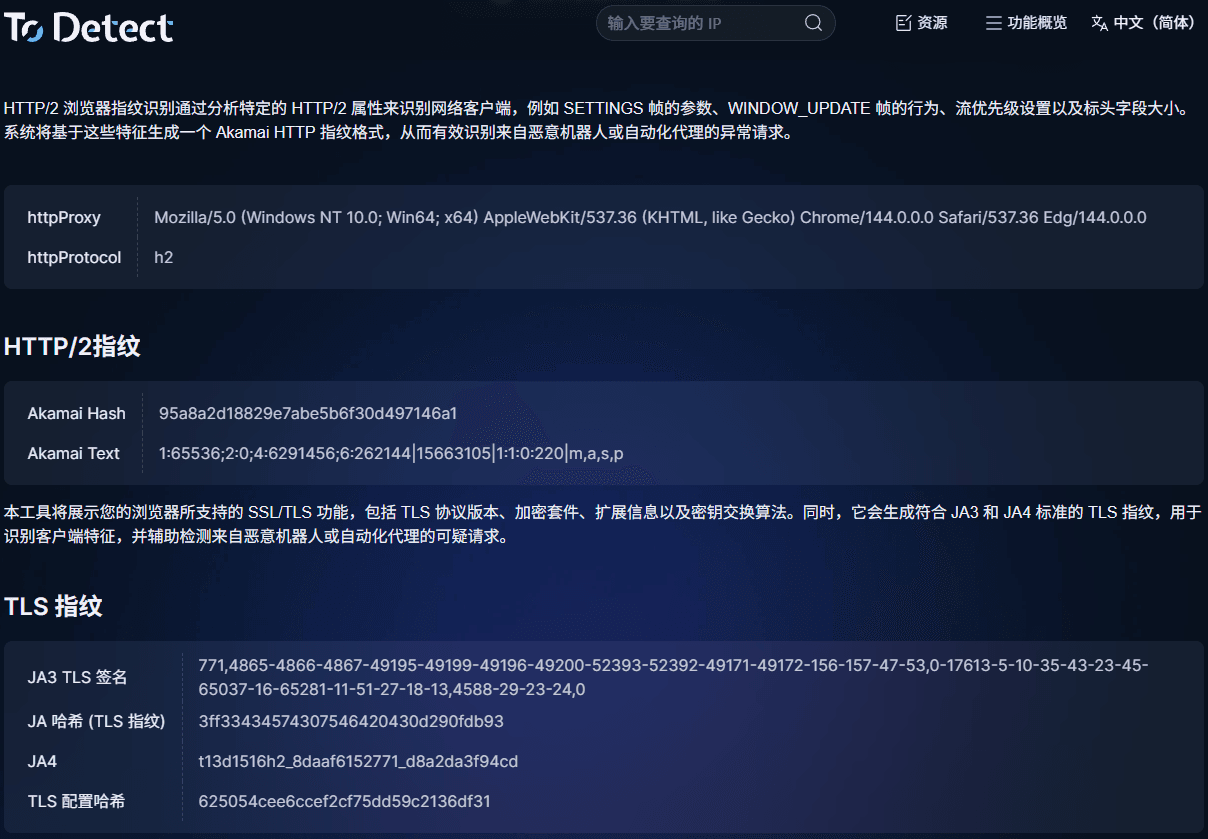
三、如何快速查詢 TLS 指紋
在調試或分析流量時,可以借助 ToDetect 指紋查詢工具:
• 查看 TLS 指紋
• 分析 HTTP2 指紋
• 檢測瀏覽器指紋特徵
• 判斷是否為自動化環境
在實際排查問題時非常方便,比如:
• 為什麼某些請求被風控攔截
• 自動化腳本哪裡暴露了
• 指紋是否與真實瀏覽器一致
四、實戰建議:如何搭建一套有效的指紋風控體系
第一層:基礎流量識別(快速篩選)
這一層的目標不是精準識別,而是快速過濾明顯異常的流量,減少後面系統的壓力。常見策略包括:
1)IP 與請求頻率控制
單 IP 請求頻率限制、同網段高並發訪問識別、數據中心 IP 標記。例如:
正常用戶:1分鐘內訪問 10~30 次
異常腳本:1分鐘內訪問上百次甚至上千次
這種情況可以直接觸發:限速、滑塊驗證、臨時封禁。
2)User-Agent 與基礎 Header 檢測
檢查一些明顯不合理的情況,例如:空 UA、UA 與系統平台不匹配、Header 缺失關鍵字段。
例如:UA 顯示為 Chrome,但沒有 sec-ch-ua、accept-language 等關鍵頭,這種請求大概率是腳本。
這一層的特點是:實現簡單、性能開銷小、用於第一道過濾網。
第二層:指紋級識別(核心風控層)
1)TLS 指紋識別:判斷客戶端真實性
透過 JA3、JA4 等方式:建立真實瀏覽器的 TLS 指紋庫、標記常見自動化框架指紋
常見異常:UA 是 Chrome,但 TLS 指紋是 Python requests;同一帳號 TLS 指紋頻繁變化;大量請求使用相同異常指紋。
這類流量可以:降權處理 + 加驗證 + 進入風控隊列。
2)HTTP2/TLS 指紋檢測:識別偽瀏覽器
很多自動化工具在 HTTP2 層會露出破綻,比如:幀順序不符合真實瀏覽器、Header 排列異常、優先級設置缺失,這些都是典型的自動化特徵。
這一層通常可以識別:
• 無頭瀏覽器
• 自動化框架
• 模擬瀏覽器協議棧的爬蟲
第三層:行為分析(最終判定層)
即使指紋正常,也不代表一定是真人。
因為現在很多自動化工具已經可以模擬瀏覽器指紋、模擬 TLS 指紋或使用住宅代理。
所以最後一層一定要加上行為分析。常見維度包括:
1)訪問路徑
真人用戶:首頁 → 列表頁 → 詳情頁 → 登錄
爬蟲:直接訪問大量詳情頁,無導航路徑。
2)停留時間與操作節奏
真人:頁面停留時間有波動,操作節奏不規律。
腳本:固定時間間隔,操作速度過快。
例如:每 2 秒點擊一次按鈕,連續 100 次請求無停頓,這種基本可以直接判定為自動化。
總結
反爬和風控早就不再是「封 IP、改驗證碼」這麼簡單的事情了。自動化工具在表層特徵上越來越像真人,但在底層協議和環境一致性上,依然會留下痕跡。
對於實際項目來說,不一定要一步到位搭建複雜系統。更現實的做法是先從基礎規則和瀏覽器指紋入手,再引入 TLS 指紋識別作為核心識別層。
也可以借助像 ToDetect 指紋查詢工具 這樣的工具,快速查看當前環境的 TLS 指紋和瀏覽器特徵,定位問題會輕鬆很多。
 廣告
廣告

