User-Agent字符串是什麼?瀏覽器User-Agent每一段代表什麼意思
User-Agent字串很多人第一次看到時會覺得是一長串亂碼,但其實它並不複雜,甚至可以說是「瀏覽器的身份證」。
說白了,它就像瀏覽器發出去的一張「自我介紹卡片」。你用什麼裝置、什麼系統、什麼瀏覽器版本,基本都寫在這一行裡。
今天就用比較直白的方式,帶你搞懂User-Agent字串到底是什麼?以及瀏覽器User-Agent每一段分別代表什麼意思?

一、User-Agent字串到底是什麼?
User-Agent(簡稱UA)就是瀏覽器或客戶端在訪問網站時主動發送的一段標識資訊,用來告訴伺服器:「我是誰,我從哪裡來,我用的是什麼裝置」。
• 比如你用Chrome訪問一個網站,瀏覽器會自動帶上一段類似這樣的資訊:
• Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 ... Chrome/120.0.0.0 Safari/537.36
• 這段看似複雜的字串,其實就是標準的瀏覽器User-Agent。
通過User-Agent解析(UA解析),可以判斷使用者是手機還是電腦,是iOS還是Android,是Chrome還是Firefox,從而返回不同頁面或做相容性處理。
二、瀏覽器User-Agent每一段到底代表什麼?
1. Mozilla/5.0(相容標識)
這一段看起來像「火狐」,但其實大多數瀏覽器都會帶。原因是歷史相容問題,現在它更多是一個「傳統標記」,不用太糾結。
2. 作業系統資訊(核心識別點)
例如:
• Windows NT 10.0 → Windows 10系統
• Android 13 → 安卓系統版本
• Intel Mac OS X → Mac電腦
這一段在UA解析中非常關鍵,可以直接判斷使用者裝置類型。
3. CPU架構資訊
比如:Win64; x64 → 64位Windows系統;ARM64 → 手機或ARM架構裝置,這部分在做性能適配或裝置分類時很有用。
4. 渲染引擎資訊
例如AppleWebKit/537.36;Gecko(Firefox常見),這代表瀏覽器底層使用的排版引擎。很多做瀏覽器User-Agent識別的人,會重點關注這一段。
5. 瀏覽器核心資訊(最重要)
例如:Chrome/120.0.0.0;Safari/537.36;Firefox/118.0,這一段直接說明使用者使用的瀏覽器版本,是做相容性判斷的關鍵依據。
三、為什麼UA解析這麼重要?
現在很多網站不僅僅是「看使用者是誰」,還會做更深層的判斷是否為真實使用者、是否為爬蟲、是否多開帳號、是否存在自動化行為。
這時候單純看IP已經不夠了,瀏覽器指紋檢測就變得非常重要,而UA只是其中一環。
在完整的指紋體系裡Canvas指紋、WebGL資訊、字體列表、螢幕解析度、時區與語言,綜合起來,形成一個「裝置畫像」。
所以你會看到很多風控系統都會做User-Agent解析 + 瀏覽器指紋檢測 = 使用者真實性判斷。
四、瀏覽器User-Agent在實際業務中的用途
1. 行動端 / PC端適配
最常見的用途就是根據UA判斷裝置,然後跳轉不同頁面。比如手機 → m.xxx.com;電腦 → www.xxx.com。
2. 數據統計分析
很多統計工具會通過UA判斷使用者裝置分佈,比如:Android佔比多少、iPhone佔比多少、Chrome是否為主流瀏覽器。
3. 風控與反爬
很多爬蟲會偽造User-Agent,但如果只改UA是不夠的,因為還會結合:瀏覽器指紋檢測、行為軌跡分析、請求頻率,因此單純修改UA已經很難「偽裝成真人」。
五、瀏覽器UA解析的常見誤區
誤區1:UA可以完全識別使用者身份
很多人以為通過User-Agent就能唯一定位使用者,但實際上它只能提供裝置和瀏覽器資訊,無法作為身份標識。
誤區2:修改UA就能實現完美偽裝
即使更改瀏覽器User-Agent字串,現代網站仍會結合瀏覽器指紋檢測等多維數據識別真實環境。
誤區3:UA越複雜說明資訊越準確
UA字串長度與複雜度並不代表可靠性,反而可能因為拼接資訊過多導致解析誤差。
誤區4:所有瀏覽器UA結構都是統一的
不同瀏覽器核心(如Chrome、Firefox、Safari)的UA格式存在差異,不能用單一規則解析。
誤區5:UA資訊是完全可信的
UA本質上是客戶端可偽造的欄位,因此在風控和反爬場景中不能單獨作為判斷依據。
誤區6:行動端和PC端UA很好區分且不會變化
實際中很多瀏覽器支援「桌面模式」或「響應式UA切換」,UA並不總是固定對應裝置類型。
誤區7:UA解析可以替代瀏覽器指紋檢測
UA解析只是基礎資訊識別,而瀏覽器指紋檢測才是判斷裝置真實性的核心手段。
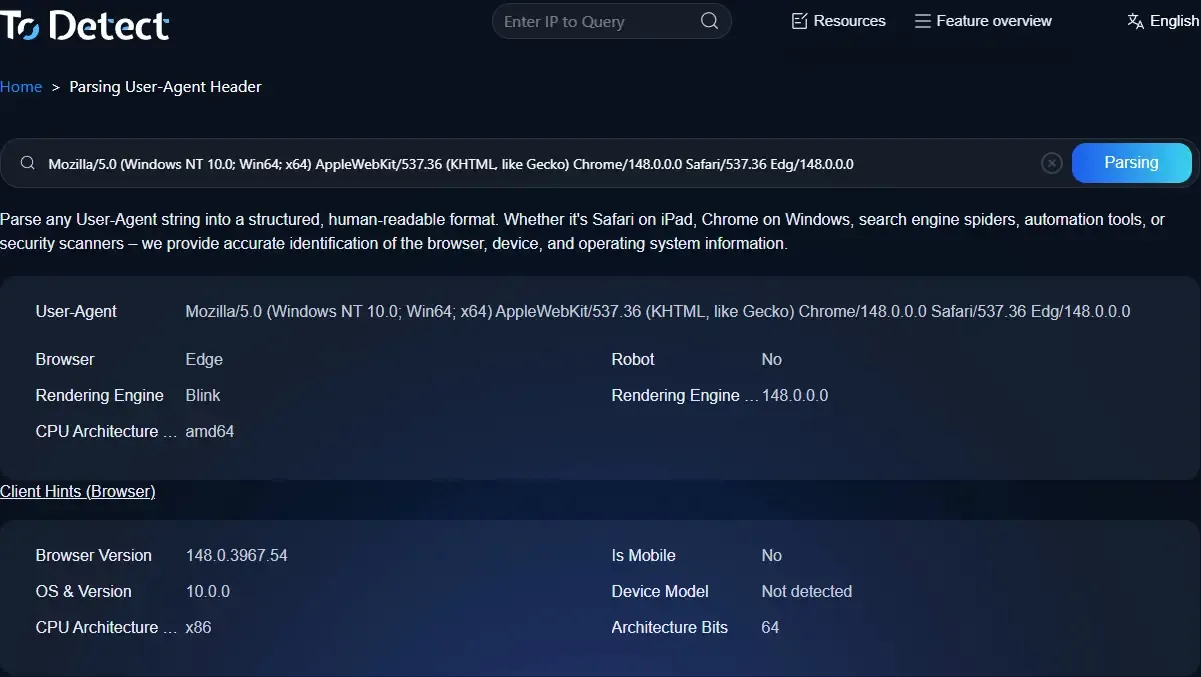
六、ToDetect這類工具在UA分析中的作用
在實際開發或風控測試中,很多人會用類似 ToDetect 這樣的工具來查看瀏覽器指紋和UA資訊。
• 檢測當前UA是否真實
• 查看瀏覽器指紋是否異常
• 模擬不同裝置環境
• 分析是否存在偽裝行為
對於做反爬、廣告投放優化或者跨境電商營運的人來說,這類工具可以幫助快速驗證環境是否「乾淨」。
總結:UA只是起點,不是終點
看到這裡,相信你對User-Agent已經不再陌生了。它看起來只是一段瀏覽器附帶的字串,但實際上在真實的網際網路環境裡,它的作用遠比想像中複雜。
現在無論是平台風控還是數據分析,不只是看User-Agent解析,還會結合裝置指紋、行為特徵、環境一致性等多個維度一起判斷。
像 ToDetect 瀏覽器檢測工具本質上就是在幫你把這些資訊結構化,讓你更快看清「這個訪問到底像不像真人」。




