User-Agent vs. IP 주소: 핵심 차이점 설명 – 역할을 한눈에 이해하기
많은 사람들은 처음 이 두 가지 개념을 접할 때 혼란을 느낍니다 — 둘 다 “사용자 정보”처럼 보이지만 실제로는 완전히 다른 목적을 갖습니다.
사실 이해하는 것은 전혀 복잡하지 않습니다. 핵심은 하나는 “어떤 디바이스를 쓰고 있는지”를, 다른 하나는 “어떤 네트워크에서 오고 있는지”를 나타낸다는 점입니다.
오늘은 User-Agent가 무엇을 드러내는지, IP 주소가 어떤 정보를 노출할 수 있는지, 그리고 두 가지의 핵심 차이를 분명히 이해하도록 돕겠습니다.

1. 먼저, User-Agent와 IP 주소는 정확히 무엇인가요?
1. User-Agent란?
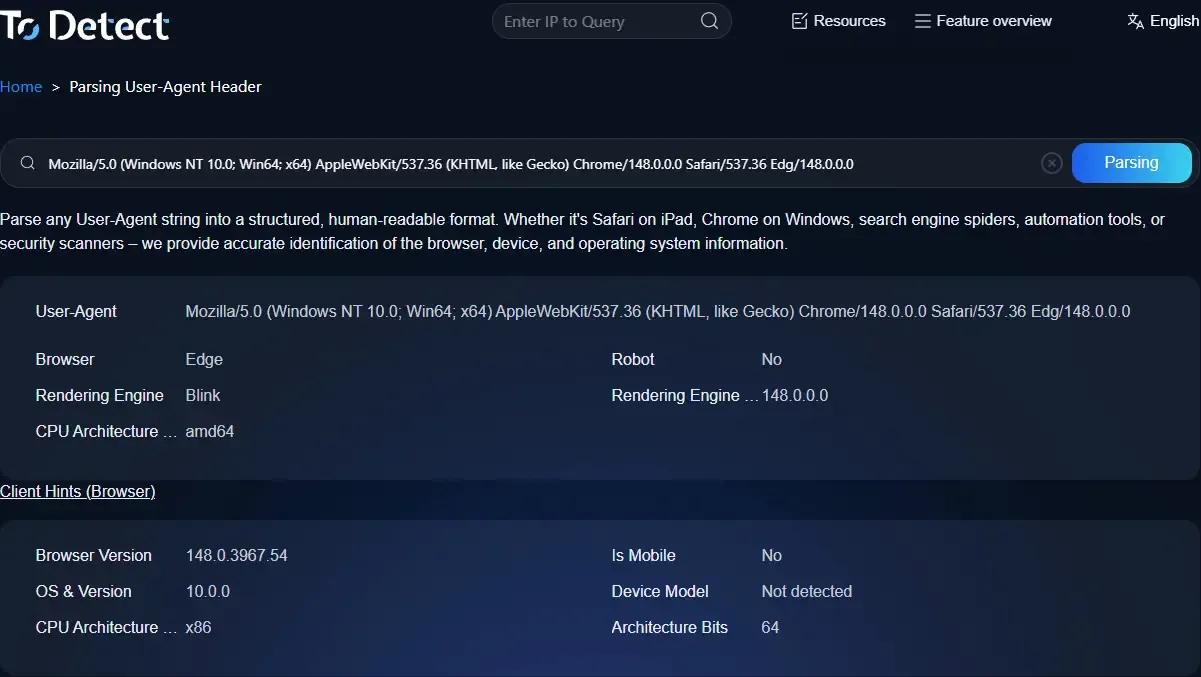
User-Agent(UA)는 기본적으로 브라우저가 웹사이트에 보내는 “소개 카드”입니다. 이는 서버에 다음을 알려줍니다:
• 사용 중인 브라우저 (Chrome, Edge, Safari)
• 사용 중인 디바이스 (휴대폰, 데스크톱, 태블릿)
• 사용 중인 운영체제 (Windows, iOS, Android)
• 일반적인 UA 문자열은 다음과 같습니다:
• Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/122...
따라서 User-Agent 파싱을 수행할 때의 본질은 이 긴 문자열을 읽을 수 있는 데이터로 변환하여 방문자의 디바이스 유형을 식별하는 것입니다.
2. IP 주소란?
IP 주소는 인터넷에서의 주소와 같습니다. 대략적인 위치, 사용 중인 네트워크 제공자, 그리고 proxy 사용 여부를 식별합니다.
IP 조회 도구를 통해 일반적으로 도시 단위 위치 데이터(예: Guangzhou, Shanghai, Shenzhen), 네트워크 유형(China Mobile, China Unicom, China Telecom), 그리고 해당 IP가 데이터 센터 소유인지 여부를 확인할 수 있습니다.
2. User-Agent vs IP 주소: 핵심 차이 한눈에 보기
| 비교 항목 | User-Agent (UA) | IP 주소 |
|---|---|---|
| 정의 | 클라이언트가 보내는 브라우저/디바이스 식별 문자열 | 네트워크에서의 고유 통신 주소 |
| 주요 목적 | 디바이스 유형, 브라우저, 운영체제 식별 | 사용자 네트워크 위치와 출처 식별 |
| 정보 계층 | 디바이스 레벨 정보 | 네트워크 레벨 정보 |
| 변조 가능 여부 | 매우 쉽게 변경됨(UA 스푸핑이 흔함) | proxies/VPNs를 통해 숨기거나 변경 가능 |
| 정확도 | 디바이스 유형은 식별 가능하나 개인은 불가 | 도시 및 ISP 레벨 정보 파악 가능 |
| 안정성 | 비교적 안정적이나 스크립트로 조작 가능 | 모바일 네트워크 환경에서 자주 변경될 수 있음 |
| 일반적 활용 | 디바이스 인식, 모바일 최적화, 트래픽 분석 | 지역 감지, 리스크 통제, 봇 방지 |
| SEO 활용 | Baidu spiders, Googlebot, 모바일 트래픽 식별 | 지역별 트래픽, 비정상 방문, 가짜 트래픽 탐지 |
| 보안적 가치 | 중간(스푸핑이 쉬움) | 상대적으로 높음(기본 리스크 통제에 유용) |
| 일반 도구 | User-Agent 파서, 브라우저 감지 도구 | IP 조회 도구, IP 지리적 위치 서비스 |
3. 왜 웹사이트는 UA와 IP를 함께 분석할까요?
IP만 보면 오판하기 쉽습니다. UA만 보면 보안이 여전히 불충분합니다. 예를 들어:
• 같은 IP로 빈번히 접속하지만 UA가 계속 바뀜 → 봇일 가능성
• UA는 정상처럼 보이나 IP가 이례적 지역에서 옴 → proxy 트래픽일 가능성
• IP와 UA 모두 수상함 → 고위험 접근
그래서 많은 최신 시스템은 브라우저 fingerprint 감지도 함께 결합합니다.
4. 브라우저 fingerprinting: UA와 IP를 넘어서는 방법
UA와 IP가 “기본 정보”라면, 브라우저 fingerprinting은 업그레이드된 식별 방식입니다.
설치된 폰트, 화면 해상도, 시간대/언어 설정, Canvas 렌더링 특성, WebGL 정보 등 여러 유형의 데이터를 결합합니다.
많은 리스크 통제 시스템과 광고 플랫폼이 UA와 IP 분석의 약점을 보완하고 식별 정확도를 높이기 위해 이 방식을 사용합니다.
5. 실제 활용: 기술 전문가만을 위한 것이 아닙니다
1. SEO 분석과 트래픽 식별
SEO 담당자는 종종 UA 분석으로 검색 엔진 크롤러(Baidu Spider, Googlebot)를 식별하고, 모바일과 데스크톱 트래픽 분포를 분석합니다.
IP 조회와 결합하면 비정상 트래픽이나 클릭 사기 행위를 감지하는 데에도 도움이 됩니다.
2. 웹사이트 보안과 리스크 통제
전자상거래 플랫폼과 로그인 시스템은 사기 및 크리덴셜 스터핑 위험을 줄이기 위해 IP 블랙리스트, UA 이상 탐지, 브라우저 fingerprint 매칭을 함께 사용합니다.
3. 데이터 분석과 사용자 인사이트
예를 들어 사용자들이 주로 어떤 디바이스를 사용하는지, 어떤 지역에서 트래픽이 가장 많이 발생하는지, 또는 proxy 트래픽이 데이터에 영향을 주는지 알고 싶다면 UA 파싱과 IP 분석이 필수입니다.
6. 실제 환경에서의 ToDetect 및 유사 도구의 역할
실무에서는 매번 UA 문자열을 수동으로 파싱하거나 IP를 확인하는 것은 비현실적입니다. 이런 지점에서 도구가 매우 가치가 있습니다.
브라우저 fingerprinting 플랫폼(예: ToDetect)은 다음을 빠르게 수행하도록 도와줍니다:
• User-Agent 파싱
• IP 주소 조회 및 지리적 위치 감지
• 브라우저 fingerprint 분석
• 리스크 점수 평가
웹사이트 운영자, 광고주, 안티 프로드 팀에게 이러한 도구는 효율을 크게 높여줍니다.
7. 사람들이 자주 간과하는 중요한 디테일
많은 사람들이 “IP + UA = 완전한 사용자 정보”라고 생각하지만, 이는 턱없이 부족합니다. 실제로는 몇 가지 중요한 한계가 있습니다:
1. 모바일 네트워크의 IP는 자주 바뀝습니다
모바일 사용자의 IP는 하루에도 여러 번 바뀔 수 있어 쉽게 오판을 유발할 수 있습니다.
2. UA가 실제 디바이스와 동일한 것은 아닙니다
일부 봇은 손쉽게 Chrome 또는 Safari 브라우저로 위장할 수 있습니다.
3. proxies 사용이 점점 흔해지고 있습니다
이로 인해 IP 지리적 위치의 정확도가 점점 떨어집니다. 따라서 이제는 IP나 UA만으로는 충분하지 않으며 — 브라우저 fingerprinting도 포함해야 합니다.
8. User-Agent와 IP 주소에 대한 자주 묻는 질문(FAQ)
1. 실제 사용자를 식별하는 데 더 좋은 것은 무엇인가요: User-Agent인가, IP 주소인가?
일반적으로 어느 것 하나만으로는 실제 사용자를 독립적으로 식별할 수 없습니다. User-Agent는 쉽게 스푸핑될 수 있고, IP 주소는 proxies나 VPN을 통해 변경될 수 있습니다.
오늘날 더 신뢰할 수 있는 방법은 User-Agent 파싱, IP 주소 분석, 브라우저 fingerprint 감지를 함께 결합하는 것입니다.
2. IP 주소로 개인을 정밀하게 찾을 수 있나요?
아니요. IP 주소 조회는 보통 “Shenzhen Telecom” 또는 “Shanghai Mobile”과 같은 도시 또는 ISP 수준의 정보만 제공합니다.
개인의 정확한 물리적 주소를 직접 식별할 수 없으므로 주로 리스크 통제, 지역 분석, 트래픽 평가에 사용됩니다.
3. User-Agent는 변경될 수 있나요? 웹사이트 분석에 영향을 주나요?
예, 그리고 매우 쉽습니다. 브라우저 확장 프로그램이나 스크립트로 UA 문자열을 손쉽게 스푸핑할 수 있습니다.
이는 실제로 웹사이트 분석, 특히 디바이스 인식과 모바일 트래픽 통계를 방해할 수 있습니다. 그래서 많은 플랫폼이 추가적인 검증 차원을 사용합니다.
4. 왜 많은 웹사이트가 IP와 User-Agent 파싱 을 함께 분석하나요?
단일 차원에만 의존하면 우회가 쉽기 때문입니다. IP 주소는 지리적 출처를 파악하는 데 도움을 주고, User-Agent는 디바이스 유형을 식별하는 데 도움을 줍니다. 함께 사용할 때 비정상 트래픽, 봇, 의심스러운 행동을 감지하는 데 훨씬 효과적입니다.
결론: 개념을 암기하는 것보다 본질을 이해하는 것이 중요합니다
IP와 UA는 단순해 보이지만, 드러낼 수 있는 정보의 양은 대부분이 상상하는 것보다 훨씬 큽니다. 오늘날의 인터넷 환경에서는 단일 데이터 포인트에 의존하는 것으로는 충분하지 않습니다.
진정으로 신뢰할 수 있는 접근은 IP 주소 조회, User-Agent 파싱, 브라우저 fingerprint 감지를 결합하여 종합적으로 분석하는 것입니다.
ToDetect와 같은 도구는 이러한 단편적 정보를 통합하고 다차원 교차 검증을 수행하여 단일 신호에만 의존하지 않고 식별 정확도를 향상시키도록 설계되었습니다.




