User-Agent vs. dirección IP: diferencias clave explicadas – comprende sus funciones de un vistazo
Muchas personas se sienten confundidas la primera vez que se encuentran con estos dos conceptos — ambos parecen “información del usuario”, pero en realidad cumplen propósitos completamente diferentes.
De hecho, entenderlos no es nada complicado. La clave es saber que uno representa “qué dispositivo estás usando”, mientras que el otro representa “de qué red vienes”.
Hoy te ayudaremos a entender con claridad qué puede revelar User-Agent, qué información puede exponer una dirección IP y las diferencias clave entre ambos.

1. Primero, ¿qué son exactamente User-Agent y la dirección IP?
1. ¿Qué es User-Agent?
User-Agent (UA) es básicamente una “tarjeta de presentación” que tu navegador envía a un sitio web. Le dice al servidor:
• Qué navegador estás usando (Chrome, Edge, Safari)
• Qué dispositivo estás usando (teléfono, escritorio, tablet)
• Qué sistema operativo estás usando (Windows, iOS, Android)
• Una cadena UA común puede verse así:
• Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/122...
Así que, al realizar análisis de User-Agent, la esencia es simplemente convertir esta cadena larga en datos legibles para identificar el tipo de dispositivo del visitante.
2. ¿Qué es una dirección IP?
Una dirección IP es como tu dirección en Internet. Identifica aproximadamente dónde te encuentras, qué proveedor de red utilizas y si podrías estar usando un proxy.
A través de herramientas de consulta de IP, normalmente puedes ver datos de ubicación a nivel de ciudad (como Guangzhou, Shanghai o Shenzhen), el tipo de red (China Mobile, China Unicom, China Telecom) y si la IP pertenece a un centro de datos.
2. User-Agent vs dirección IP: las diferencias clave de un vistazo
| Dimensión de comparación | User-Agent (UA) | Dirección IP |
|---|---|---|
| Definición | Una cadena de identidad de navegador/dispositivo enviada por el cliente | Una dirección de comunicación única en la red |
| Propósito principal | Identificar tipo de dispositivo, navegador y sistema operativo | Identificar la ubicación de red y el origen del usuario |
| Capa de información | Información a nivel de dispositivo | Información a nivel de red |
| ¿Se puede modificar? | Muy fácil de modificar (la suplantación de UA es común) | Puede ocultarse o cambiarse mediante proxies/VPNs |
| Precisión | Puede identificar el tipo de dispositivo pero no a una persona | Puede ubicar información a nivel de ciudad e ISP |
| Estabilidad | Relativamente estable pero puede ser manipulado por scripts | Puede cambiar con frecuencia en entornos de redes móviles |
| Usos comunes | Reconocimiento de dispositivos, adaptación móvil, analítica de tráfico | Detección geográfica, control de riesgos, protección anti-bot |
| Aplicaciones SEO | Identificar arañas de Baidu, Googlebot, tráfico móvil | Detectar tráfico regional, visitas anómalas, tráfico falso |
| Valor de seguridad | Medio (fácil de suplantar) | Relativamente alto (útil para el control de riesgos básico) |
| Herramientas comunes | Analizadores de User-Agent, herramientas de detección de navegador | Herramientas de consulta de IP, servicios de geolocalización de IP |
3. ¿Por qué los sitios web analizan UA e IP juntos?
Si solo miras las IP, es fácil equivocarse. Si solo miras las UA, la seguridad sigue siendo insuficiente. Por ejemplo:
• La misma IP accede con frecuencia, pero la UA sigue cambiando → posiblemente un bot
• La UA parece normal, pero la IP proviene de una región inusual → posiblemente tráfico de proxy
• Tanto la IP como la UA se ven sospechosas → acceso de alto riesgo
Por eso muchos sistemas modernos también combinan la detección de fingerprint del navegador.
4. Browser fingerprinting: más allá de UA e IP
Si UA e IP se consideran “información básica”, el fingerprinting del navegador es un método de identificación mejorado.
Combina múltiples tipos de datos, incluidos las fuentes instaladas, la resolución de pantalla, la configuración de zona horaria/idioma, las características de renderizado de Canvas y la información de WebGL.
Muchos sistemas de control de riesgos y plataformas publicitarias ahora utilizan este enfoque para compensar las debilidades del análisis de UA e IP y mejorar la precisión de la identificación.
5. Aplicaciones del mundo real: no solo para expertos técnicos
1. Análisis SEO e identificación de tráfico
Los profesionales de SEO suelen usar el análisis de UA para identificar rastreadores de motores de búsqueda (como Baidu Spider y Googlebot) y analizar la distribución del tráfico móvil vs. de escritorio.
Combinado con la consulta de IP, también puede ayudar a detectar tráfico anómalo o comportamientos de fraude de clics.
2. Seguridad del sitio web y control de riesgos
Las plataformas de comercio electrónico y los sistemas de inicio de sesión suelen usar listas negras de IP, detección de anomalías de UA y coincidencia de fingerprint del navegador juntas para reducir el fraude y los riesgos de credential stuffing.
3. Analítica de datos e información de usuarios
Por ejemplo, si quieres saber qué dispositivos usan principalmente los usuarios, qué regiones generan más tráfico o si el tráfico de proxy está afectando tus datos, el análisis de UA y el análisis de IP son esenciales.
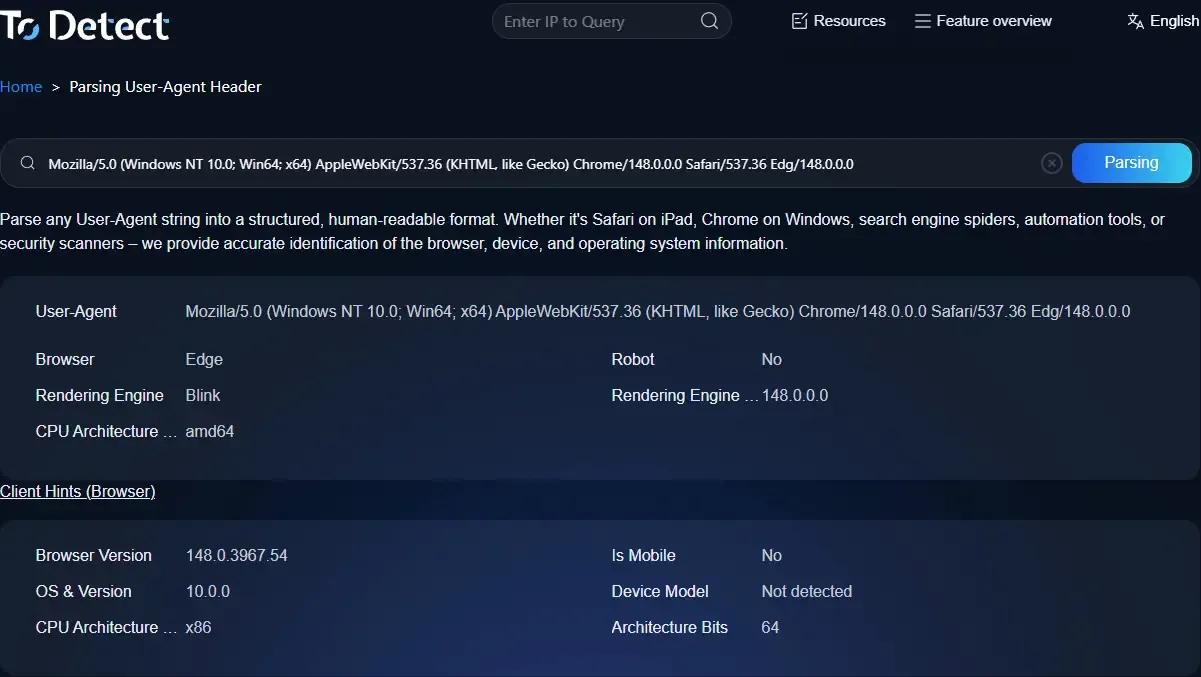
6. El papel práctico de ToDetect y herramientas similares
En operaciones reales, analizar manualmente cadenas de UA o verificar IPs cada vez no es realista. Ahí es donde las herramientas se vuelven extremadamente valiosas.
Las plataformas de fingerprinting del navegador (como ToDetect) pueden ayudarte a completar rápidamente:
• Análisis de User-Agent
• Consulta de direcciones IP y detección de geolocalización
• Análisis de fingerprint del navegador
• Evaluación de puntuación de riesgo
Para operadores de sitios web, anunciantes o equipos antifraude, estas herramientas pueden mejorar significativamente la eficiencia.
7. Detalles importantes que la gente suele ignorar
Mucha gente piensa “IP + UA = información completa del usuario”, pero eso está lejos de ser suficiente. En realidad, hay varias limitaciones importantes:
1. Las IP de redes móviles cambian con frecuencia
La IP de un usuario móvil puede cambiar varias veces al día, lo que puede causar fácilmente juicios erróneos.
2. UA no equivale a un dispositivo real
Algunos bots pueden disfrazarse fácilmente como navegadores Chrome o Safari.
3. Los proxies se están volviendo más comunes
Esto hace que la geolocalización por IP sea cada vez menos precisa. Por eso confiar solo en IP o UA ya no es suficiente: también debe incluirse el fingerprinting del navegador.
8. Preguntas comunes sobre User-Agent y la dirección IP (FAQ)
1. ¿Qué es mejor para identificar usuarios reales: User-Agent o la dirección IP?
En términos generales, ninguno puede identificar de forma independiente a un usuario real. User-Agent puede suplantarse fácilmente y las direcciones IP pueden cambiar mediante proxies o VPNs.
El enfoque más fiable hoy es combinar el análisis de User-Agent, el análisis de direcciones IP y la detección de fingerprint del navegador.
2. ¿Puede una dirección IP ubicar con precisión a una persona?
No. La consulta de direcciones IP generalmente solo proporciona información a nivel de ciudad o de ISP, como “Shenzhen Telecom” o “Shanghai Mobile”.
No puede identificar directamente la dirección física exacta de una persona, por lo que se utiliza principalmente para control de riesgos, análisis regional y evaluación de tráfico.
3. ¿Se puede modificar User-Agent? ¿Afectará a la analítica del sitio web?
Sí, y es muy fácil. Las extensiones del navegador o los scripts pueden suplantar cadenas de UA sin esfuerzo.
Esto puede interferir con la analítica del sitio, especialmente el reconocimiento de dispositivos y las estadísticas de tráfico móvil. Por eso muchas plataformas ahora utilizan dimensiones adicionales de verificación.
4. ¿Por qué muchos sitios web analizan tanto IP como análisis de User-Agent juntos?
Porque confiar en una sola dimensión es fácil de eludir. Las direcciones IP ayudan a determinar el origen geográfico, mientras que User-Agent ayuda a identificar el tipo de dispositivo. Juntos, son mucho más eficaces para detectar tráfico anómalo, bots y comportamientos sospechosos.
Conclusión: entender la esencia importa más que memorizar conceptos
Aunque IP y UA puedan parecer simples, la cantidad de información que pueden revelar es mucho mayor de lo que la mayoría imagina. En el entorno de Internet actual, confiar en un único dato ya no es suficiente.
Un enfoque verdaderamente fiable combina la consulta de direcciones IP, el análisis de User-Agent y la detección de fingerprint del navegador para un análisis integral.
Herramientas como ToDetect están diseñadas para integrar estas piezas de información fragmentadas, realizar verificación cruzada multidimensional y mejorar la precisión de la identificación en lugar de depender de una sola señal.




